I am a third-year Ph.D. student at HAN LAB of MIT EECS, advised by Prof. Song Han. My research interest is systems and machine learning (SysML). During my Ph.D. study, I work with my labmates on designing efficient 3D deep learning primitives (PVConv, NeurIPS’19 spotlight), networks (SPVNAS, ECCV’20 and TPAMI’21), inference libraries (TorchSparse, MLSys’22) and specialized accelerators (PointAcc, MICRO’21). We then apply them in real-world auto-driving applications (BEVFusion, ICRA’23).
I did my master of science in EECS at MIT in 2022. Before that, I graduated with highest honor from the Department of Computer Science and Engineering of Shanghai Jiao Tong University in 2020, where I was fortunately advised by Prof. Hongtao Lu. I was also affiliated with the IEEE Honor Class at SJTU.
News
| Apr 30, 2023 |
I am going to intern at Waymo Research this summer and work on exciting projects in behavior prediction. See you in Mountain View, CA!
|
| May 28, 2022 |
Check out our latest research BEVFusion, an efficient and generic multi-task multi-sensor fusion framework for 3D perception. Code has been released at here.
|
| Jan 14, 2022 |
TorchSparse is accepted to MLSys 2022!
|
| Sep 7, 2021 |
Two recent journal papers on efficient deep learning and PVNAS are accepted to TODAES and TPAMI!
|
| Jul 15, 2021 |
Recent papers SemAlign and PointAcc are accepted to IROS 2021 and MICRO 2021!
|
Recent Publications
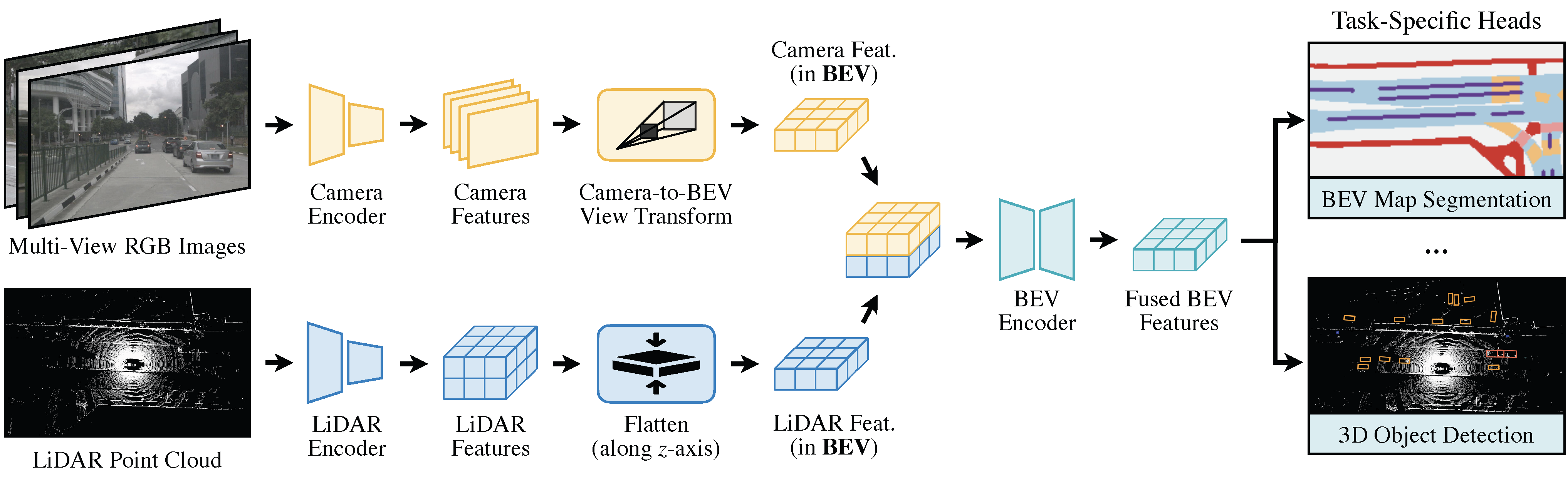
BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation
Zhijian Liu*,
Haotian Tang*,
Alexander Amini,
Xinyu Yang,
Huizi Mao,
Daniela Rus,
and Song Han
ICRA
2023
[Abs]
[arXiv]
[Website]
[Code]
Multi-sensor fusion is essential for an accurate and reliable autonomous driving system. Recent approaches are based on point-level fusion: augmenting the LiDAR point cloud with camera features. However, the camera-to-LiDAR projection throws away the semantic density of camera features, hindering the effectiveness of such methods, especially for semantic-oriented tasks (such as 3D scene segmentation). In this paper, we break this deeply-rooted convention with BEVFusion, an efficient and generic multi-task multi-sensor fusion framework. It unifies multi-modal features in the shared bird’s-eye view (BEV) representation space, which nicely preserves both geometric and semantic information. To achieve this, we diagnose and lift key efficiency bottlenecks in the view transformation with optimized BEV pooling, reducing latency by more than 40x. BEVFusion is fundamentally task-agnostic and seamlessly supports different 3D perception tasks with almost no architectural changes. It establishes the new state of the art on nuScenes, achieving 1.3% higher mAP and NDS on 3D object detection and 13.6% higher mIoU on BEV map segmentation, with 1.9x lower computation cost.
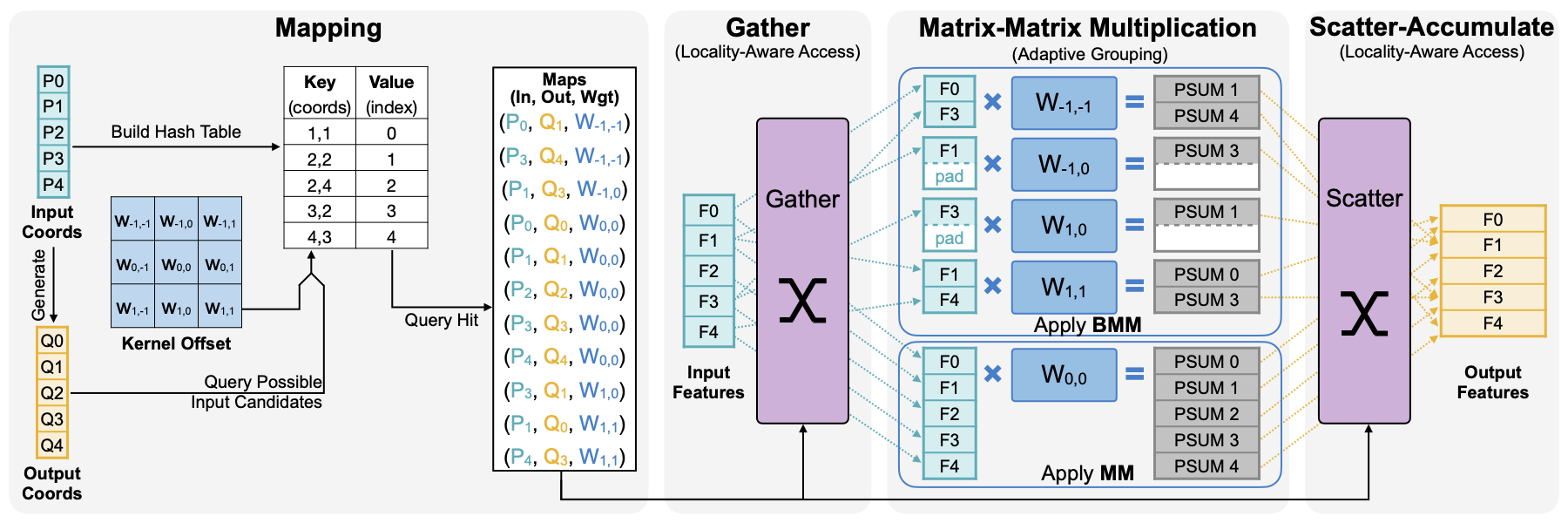
TorchSparse: Efficient Point Cloud Inference Engine
Haotian Tang*,
Zhijian Liu*,
Xiuyu Li*,
Yujun Lin,
and Song Han
MLSys
2022
[Abs]
[arXiv]
[Website]
[PDF]
[Code]
Deep learning on point clouds has received increased attention thanks to its wide applications in AR/VR and autonomous driving. These applications require low latency and high accuracy to provide real-time user experience and ensure user safety. Unlike conventional dense workloads, the sparse and irregular nature of point clouds poses severe challenges to running sparse CNNs efficiently on the general-purpose hardware, and existing sparse acceleration techniques for 2D images do not translate to 3D point clouds. In this paper, we introduce TorchSparse, a high-performance point cloud inference engine that accelerates the sparse convolution computation on GPUs. TorchSparse directly optimizes the two bottlenecks of sparse convolution: data movement and irregular computation. It optimizes the data orchestration by quantization and fused locality-aware memory access, reducing the memory movement cost by 2.7x. It also adopts adaptive MM grouping to trade computation for better regularity, achieving 1.4-1.5x speedup for matrix multiplication. Evaluated on seven representative models across three benchmark datasets, TorchSparse achieves 1.6x and 1.5x measured end-to-end speedup over the state-of-the-art MinkowskiEngine and SpConv, respectively.
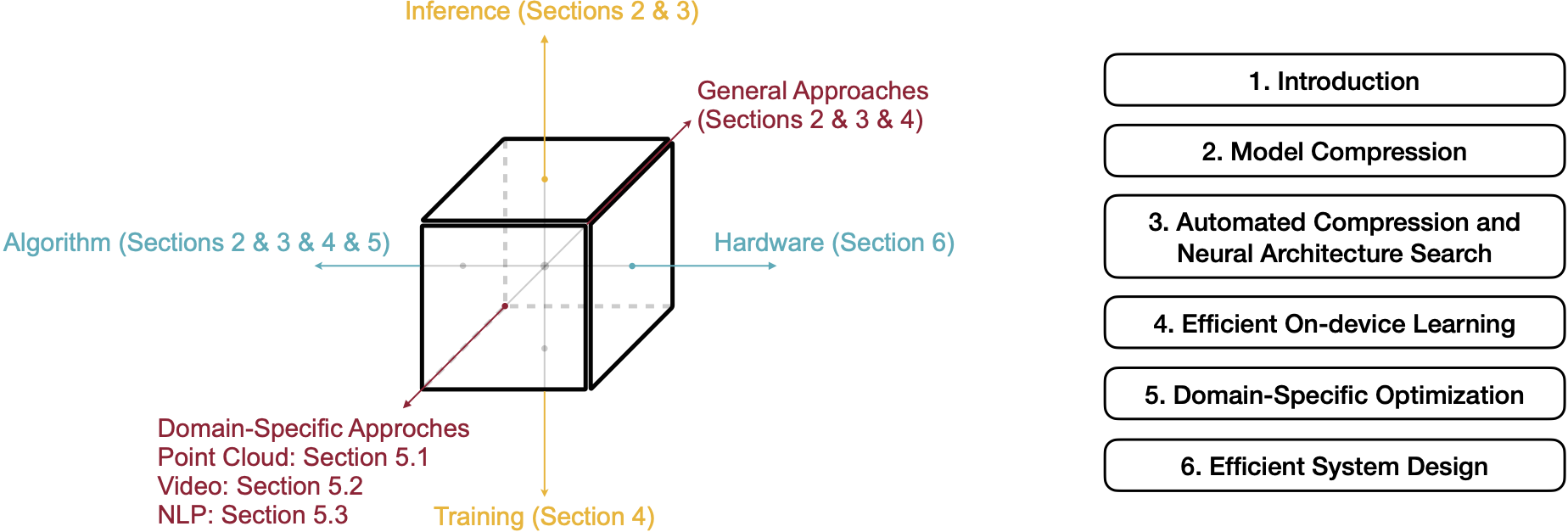
Enable Deep Learning on Mobile Devices: Methods, Systems, and Applications
Han Cai*,
Ji Lin*,
Yujun Lin*,
Zhijian Liu*,
Haotian Tang*,
Hanrui Wang*,
Ligeng Zhu*,
and Song Han
ACM Transactions on Design Automation of Electronic Systems (TODAES)
2022
[Abs]
[arXiv]
[PDF]
Deep neural networks (DNNs) have achieved unprecedented success in the field of artificial intelligence (AI), including computer vision, natural language processing and speech recognition. However, their superior performance comes at the considerable cost of computational complexity, which greatly hinders their applications in many resource-constrained devices, such as mobile phones and Internet of Things (IoT) devices. Therefore, methods and techniques that are able to lift the efficiency bottleneck while preserving the high accuracy of DNNs are in great demand in order to enable numerous edge AI applications.
This paper provides an overview of efficient deep learning methods, systems and applications. We start from introducing popular model compression methods, including pruning, factorization, quantization as well as compact model design. To reduce the large design cost of these manual solutions, we discuss the AutoML framework for each of them, such as neural architecture search (NAS) and automated pruning and quantization. We then cover efficient on-device training to enable user customization based on the local data on mobile devices. Apart from general acceleration techniques, we also showcase several task-specific accelerations for point cloud, video and natural language processing by exploiting their spatial sparsity and temporal/token redundancy. Finally, to support all these algorithmic advancements, we introduce the efficient deep learning system design from both software and hardware perspectives.
PVNAS: 3D Neural Architecture Search with Point-Voxel Convolution
Zhijian Liu*,
Haotian Tang*,
Shengyu Zhao,
Kevin Shao,
and Song Han
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
2021
[Abs]
[arXiv]
[PDF]
3D neural networks are widely used in real-world applications (e.g., AR/VR headsets, self-driving cars). They are required to be fast and accurate; however, limited hardware resources on edge devices make these requirements rather challenging. Previous work processes 3D data using either voxel-based or point-based neural networks, but both types of 3D models are not hardware-efficient due to the large memory footprint and random memory access. In this paper, we study 3D deep learning from the efficiency perspective. We first systematically analyze the bottlenecks of previous 3D methods. We then combine the best from point-based and voxel-based models together and propose a novel hardware-efficient 3D primitive, Point-Voxel Convolution (PVConv). We further enhance this primitive with the sparse convolution to make it more effective in processing large (outdoor) scenes. Based on our designed 3D primitive, we introduce 3D Neural Architecture Search (3D-NAS) to explore the best 3D network architecture given a resource constraint. We evaluate our proposed method on six representative benchmark datasets, achieving state-of-the-art performance with 1.8-23.7x measured speedup. Furthermore, our method has been deployed to the autonomous racing vehicle of MIT Driverless, achieving larger detection range, higher accuracy and lower latency.
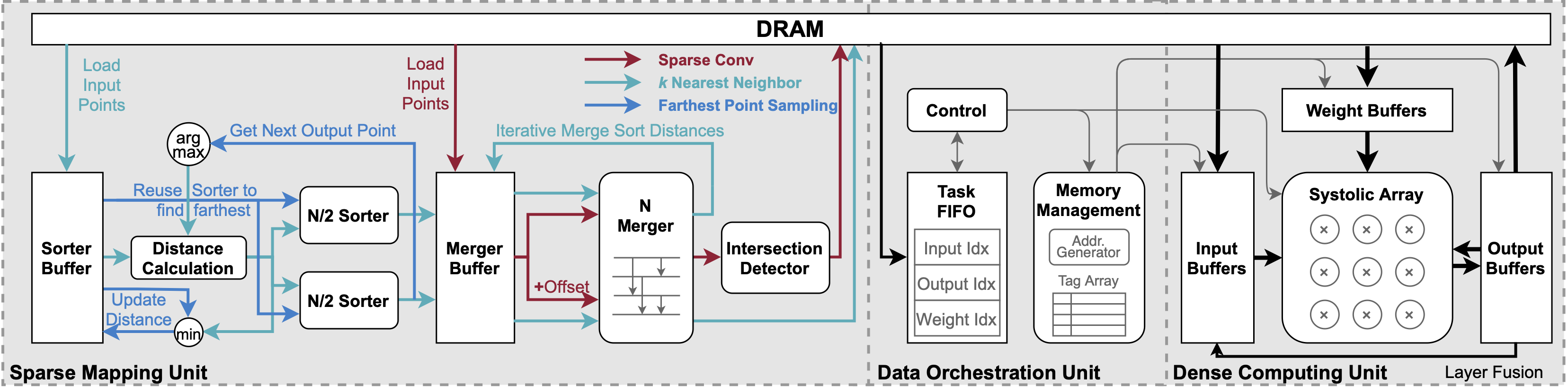
PointAcc: Efficient Point Cloud Accelerator
Yujun Lin,
Zhekai Zhang,
Haotian Tang,
Hanrui Wang,
and Song Han
MICRO
2021
[Abs]
[arXiv]
[Website]
Deep learning on point clouds plays a vital role in a wide range of applications such as autonomous driving and AR/VR. These applications interact with people in real time on edge devices and thus require low latency and low energy. However, the intrinsic sparsity of point clouds poses challenges to hardware acceleration. Mapping operations are introduced to construct output clouds and find neighbors for convolution, which are unsupported in existing deep learning accelerators. Furthermore, since points are sparsely distributed in space, point cloud convolution requires explicit gather and scatter of features, which brings large data movement overhead. In this work, we first provide a comprehensive analysis of the performance of modern point cloud networks on CPU/GPU/TPU. Then we present PointAcc, a novel point cloud deep learning accelerator.
PointAcc introduces a configurable sorting-based mapping unit that efficiently supports diverse mapping operations.
PointAcc further introduces the data orchestration that exploits simplified caching and layer fusion specialized for point cloud models, effectively reducing the DRAM access by up to 6.3x. Evaluated on 8 point cloud models across 4 different applications, our accelerator achieves 3.7x, 53x, 90x speedup and 22x, 210x, 175x energy savings over GPU, TPU, and CPU, respectively. Co-designed with efficient point cloud networks, PointAcc rivals the prior Mesorasi accelerator by 100x speedup and 9.1 mIoU accuracy improvement running segmentation task on S3DIS dataset. PointAcc paves the way for efficient point cloud recognition.
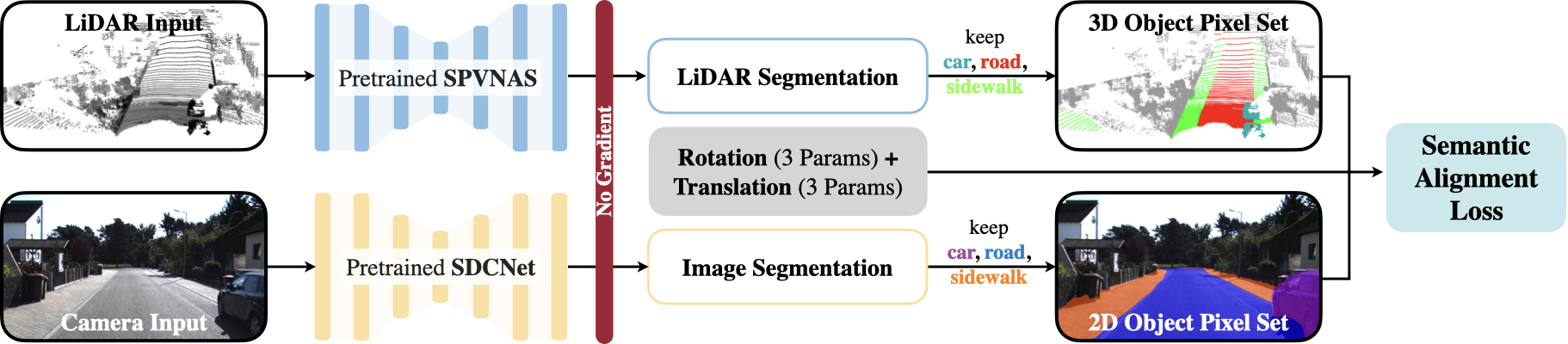
SemAlign: Annotation-Free Camera-LiDAR Calibration with Semantic Alignment Loss
Zhijian Liu*,
Haotian Tang*,
Sibo Zhu*,
and Song Han
IROS
2021
[Abs]
[Website]
[PDF]
Multi-sensor solution has been widely adopted in real-world robotics systems (e.g., self-driving vehicles) due to its better robustness. However, its performance is highly dependent on the accurate calibration between different sensors, which is very time-consuming (i.e., hours of human efforts) to acquire. Recent learning-based solutions partially address this yet still require costly ground-truth annotations as supervision. In this paper, we introduce a novel self-supervised semantic alignment loss to quantitatively measure the quality of a given calibration. It is well correlated with conventional evaluation metrics while it does not require ground-truth calibration annotations as the reference. Based on this loss, we further propose an annotation-free optimization-based calibration algorithm (SemAlign) that first estimates a coarse calibration with loss-guided initialization and then refines it with gradient-based optimization. SemAlign reduces the calibration time from hours of human efforts to only seconds of GPU computation. It not only achieves comparable performance with existing supervised learning frameworks but also demonstrates a much better generalization capability when transferred to a different dataset.
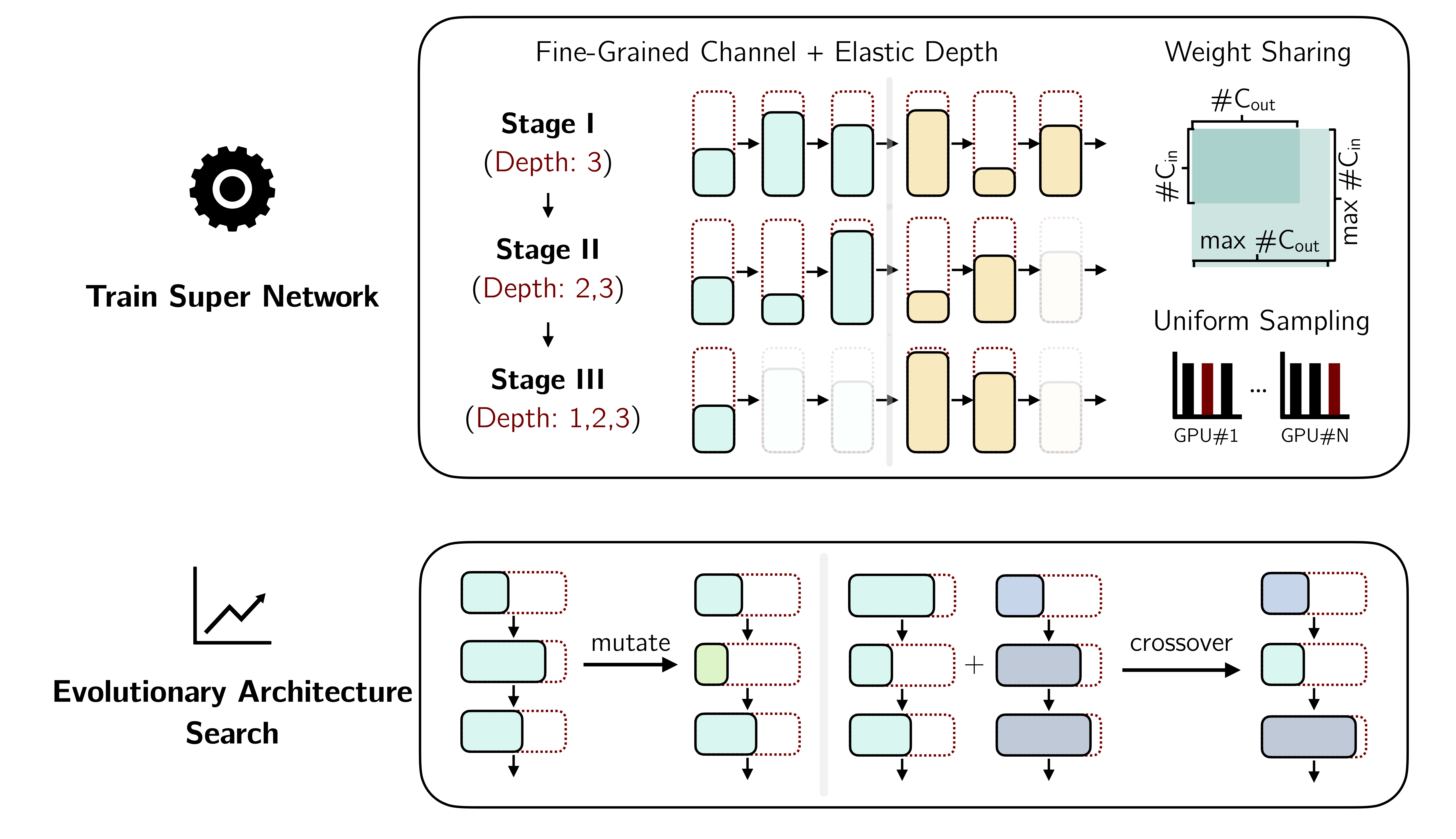
Searching Efficient 3D Architectures with Sparse Point-Voxel Convolution
Haotian Tang*,
Zhijian Liu*,
Shengyu Zhao,
Yujun Lin,
Ji Lin,
Hanrui Wang,
and Song Han
ECCV
2020
[Abs]
[arXiv]
[Website]
[Code]
Self-driving cars need to understand 3D scenes efficiently and accurately in order to drive safely. Given the limited hardware resources, existing 3D perception models are not able to recognize small instances (\eg, pedestrians, cyclists) very well due to the low-resolution voxelization and aggressive downsampling. To this end, we propose Sparse Point-Voxel Convolution (SPVConv), a lightweight 3D module that equips the vanilla Sparse Convolution with the high-resolution point-based branch. With negligible overhead, this point-based branch is able to preserve the fine details even from large outdoor scenes. To explore the spectrum of efficient 3D models, we first define a flexible architecture design space based on SPConv, and we then present 3D Neural Architecture Search (3D-NAS) to search the optimal network architecture over this diverse design space efficiently and effectively. Experimental results validate that the resulting SPVNAS model is fast and accurate: it outperforms the state-of-the-art MinkowskiNet by 3.3%, ranking 1st on the competitive SemanticKITTI leaderboard upon publication. It also achieves 8x computation reduction and 3x measured speedup over MinkowskiNet still with higher accuracy. Finally, we transfer our method to 3D object detection, and it achieves consistent improvements over the one-stage detection baseline on KITTI.
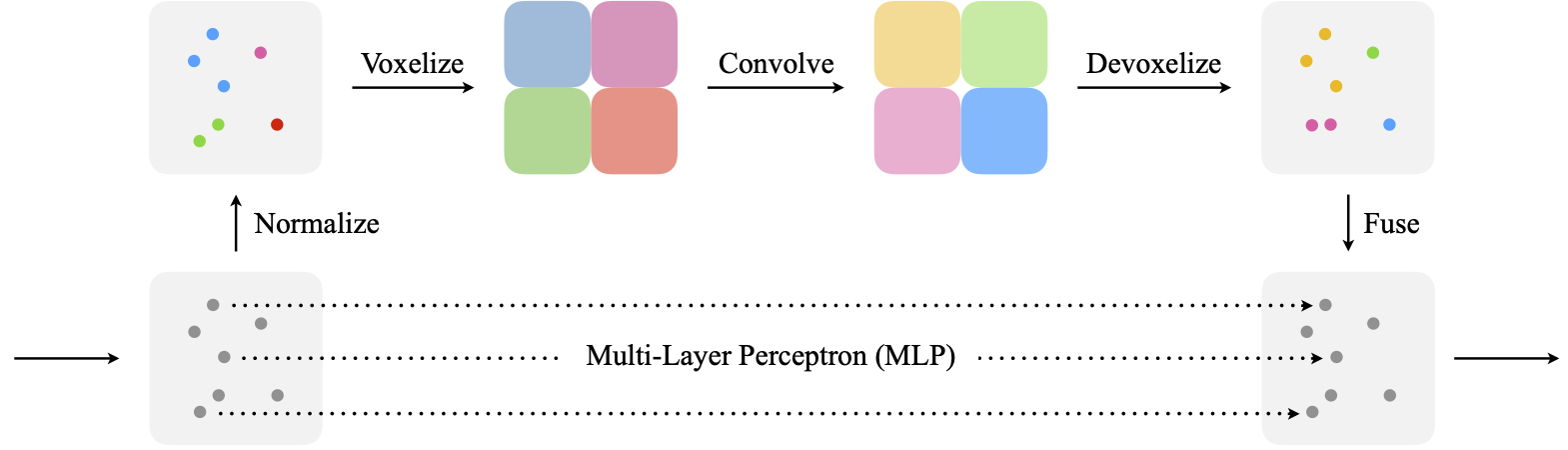
Point-Voxel CNN for Efficient 3D Deep Learning
Zhijian Liu*,
Haotian Tang*,
Yujun Lin,
and Song Han
NeurIPS (Spotlight)
2019
[Abs]
[arXiv]
[Website]
[Code]
We present Point-Voxel CNN (PVCNN) for efficient, fast 3D deep learning. Previous work processes 3D data using either voxel-based or point-based NN models. However, both approaches are computationally inefficient. The computation cost and memory footprints of the voxel-based models grow cubically with the input resolution, making it memory-prohibitive to scale up the resolution. As for point-based networks, up to 80% of the time is wasted on structuring the sparse data which have rather poor memory locality, not on the actual feature extraction. In this paper, we propose PVCNN that represents the 3D input data in points to reduce the memory consumption, while performing the convolutions in voxels to reduce the irregular, sparse data access and improve the locality. Our PVCNN model is both memory and computation efficient. Evaluated on semantic and part segmentation datasets, it achieves a much higher accuracy than the voxel-based baseline with 10x GPU memory reduction; it also outperforms the state-of-the-art point-based models with 7x measured speedup on average. Remarkably, the narrower version of PVCNN achieves 2x speedup over PointNet (an extremely efficient model) on part and scene segmentation benchmarks with much higher accuracy. We validate the general effectiveness of PVCNN on 3D object detection: by replacing the primitives in Frustrum PointNet with PVConv, it outperforms Frustrum PointNet++ by up to 2.4 mAP with 1.8 measured speedup and 1.4 GPU memory reduction.
Service
I regularly serve as a reviewer for ICML (outstanding reviewer, 2022), NeurIPS (top reviewer, 2022), ICLR (highlighted reviewer, 2022), TPAMI, IJCV, CVPR, ICCV.